
內存排序
內存排序是指CPU訪問主存時的順序。可以是編譯器在編譯時產生,也可以是CPU在運行時產生。反映了內存操作重排序,亂序執行,從而充分利用不同內存的總線帶寬。
現代處理器大都是亂序執行。因此需要內存屏障以確保多線程的同步。
編譯時內存排序
[編輯]編譯時內存屏障
[編輯]這些內存屏障阻止編譯器在編譯時亂序指令,但在運行時無效。
- GNU內聯匯編語句
asm volatile("" ::: "memory");
或者
__asm__ __volatile__ ("" ::: "memory");
- C11/C++11
atomic_signal_fence(memory_order_acq_rel);
阻止編譯器跨越它亂序讀/寫指令。[2]
- Intel_C++編譯器使用"full compiler fence"
__memory_barrier()
_ReadWriteBarrier()
運行時內存排序
[編輯]- happens-before:按照程序的代碼序執行
- synchronized-with:不同線程間,對於同一個原子操作,需要同步關係,store()操作一定要先於 load(),也就是說 對於一個原子變量x,先寫x,然後讀x是一個同步的操作
對稱多處理器(SMP)系統
[編輯]對稱多處理器(SMP)系統有多個內存一致模型。
- 順序一致(Sequential consistency):同一個線程的原子操作還是按照happens-before關係,但不同線程間的執行關係是任意
- 鬆弛一致(Relaxed consistency,允許某種類型的重排序):如果某個操作只要求是原子操作,除此之外,不需要其它同步的保障,就可以使用 Relaxed ordering。程序計數器是一種典型的應用場景
- 弱一致(Weak consistency):讀寫任意排序,受顯式的內存屏障限制。
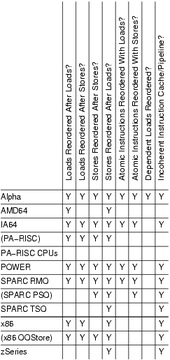
| 類型 | Alpha | ARMv7 | MIPS | LoongISA | PA-RISC | POWER | SPARC RMO | SPARC PSO | SPARC TSO | x86 | x86 oostore | AMD64 | IA-64 | z/Architecture |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loads reordered after loads | Y | Y | 架構本身不規定 微架構/芯片的實現決定 |
Y | Y | Y | Y | Y | Y | |||||
| Loads reordered after stores | Y | Y | Y | Y | Y | Y | Y | Y | ||||||
| Stores reordered after stores | Y | Y | Y | Y | Y | Y | Y | Y | Y | |||||
| Stores reordered after loads | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | |
| Atomic reordered with loads | Y | Y | Y | Y | Y | |||||||||
| Atomic reordered with stores | Y | Y | Y | Y | Y | Y | ||||||||
| Dependent loads reordered | Y | |||||||||||||
| Incoherent instruction cache pipeline | Y | Y | Y | Y | Y | Y | Y | Y | Y |
某些老的x86有更弱內存序。[8]
SPARC 內存序:
- SPARC TSO = total store order (default)
- SPARC RMO = relaxed-memory order (not supported on recent CPUs)
- SPARC PSO = partial store order (not supported on recent CPUs)
硬件內存屏障
[編輯]lfence (asm), void _mm_lfence(void) sfence (asm), void _mm_sfence(void)[9] mfence (asm), void _mm_mfence(void)[10]
sync (asm)
sync (asm)
mf (asm)
dcs (asm)
dmb (asm) dsb (asm) isb (asm)
編譯器對硬件內存屏障的支持
[編輯]- GCC,[12] version 4.4.0 and later,[13] has
__sync_synchronize. - C11/C++11
atomic_thread_fence()支持一條命令 - Microsoft Visual C++[14] has
MemoryBarrier(). - Sun Studio Compiler Suite[15] has
__machine_r_barrier,__machine_w_barrierand__machine_rw_barrier.
參見
[編輯]參考文獻
[編輯]- ^ GCC compiler-gcc.h. [2018-12-06]. (原始內容存檔於2011-07-24).
- ^ 存档副本. [2018-12-06]. (原始內容存檔於2020-08-10).
- ^ ECC compiler-intel.h. [2018-12-06]. (原始內容存檔於2011-07-24).
- ^ Intel(R) C++ Compiler Intrinsics Reference (頁面存檔備份,存於網際網路檔案館)
Creates a barrier across which the compiler will not schedule any data access instruction. The compiler may allocate local data in registers across a memory barrier, but not global data.
- ^ Visual C++ Language Reference _ReadWriteBarrier (頁面存檔備份,存於網際網路檔案館)
- ^ Memory Ordering in Modern Microprocessors by Paul McKenney (PDF). [2018-12-06]. (原始內容存檔 (PDF)於2020-10-31).
- ^ Memory Barriers: a Hardware View for Software Hackers (頁面存檔備份,存於網際網路檔案館), Figure 5 on Page 16
- ^ Table 1. Summary of Memory Ordering (頁面存檔備份,存於網際網路檔案館), from "Memory Ordering in Modern Microprocessors, Part I"
- ^ SFENCE — Store Fence. [2018-12-06]. (原始內容存檔於2019-06-13).
- ^ MFENCE — Memory Fence. [2018-12-06]. (原始內容存檔於2019-09-05).
- ^ Data Memory Barrier, Data Synchronization Barrier, and Instruction Synchronization Barrier.. [2020-12-20]. (原始內容存檔於2020-06-19).
- ^ Atomic Builtins. [2018-12-06]. (原始內容存檔於2017-11-08).
- ^ 存档副本. [2018-12-06]. (原始內容存檔於2020-10-31).
- ^ MemoryBarrier macro. [2018-12-06]. (原始內容存檔於2017-04-04).
- ^ Handling Memory Ordering in Multithreaded Applications with Oracle Solaris Studio 12 Update 2: Part 2, Memory Barriers and Memory Fence [1] (頁面存檔備份,存於網際網路檔案館)
{kind=link}
{kind=link}
進一步閱讀
[編輯]- Computer Architecture — A quantitative approach. 4th edition. J Hennessy, D Patterson, 2007. Chapter 4.6
- Sarita V. Adve, Kourosh Gharachorloo, Shared Memory Consistency Models: A Tutorial (頁面存檔備份,存於網際網路檔案館)
- Intel 64 Architecture Memory Ordering White Paper (頁面存檔備份,存於網際網路檔案館)
- Memory ordering in Modern Microprocessors part 1 (頁面存檔備份,存於網際網路檔案館)
- Memory ordering in Modern Microprocessors part 2 (頁面存檔備份,存於網際網路檔案館)
- YouTube上的IA (Intel Architecture) Memory Ordering - Google Tech Talk